“Theoretical physics is mathematics without proofs, and physics without experiments.”
We introduce physics-intern, an AI scaffolding system for autonomous research in theoretical physics. By decomposing a problem and dispatching its parts to dedicated subagents emulating a research ecosystem, we substantially improve the ability of LLMs to solve hard physics problems.
On the CritPt benchmark, performance climbs from 8.6% to 15.7% for Gemini 3 Flash, from 8.0% to 21.4% for Kimi K2.6, and from 17.7% to 31.4% for Gemini 3.1 Pro, setting a new state-of-the-art on the CritPt leaderboard.
What’s in this post. We start with CritPt, a research-level theoretical physics benchmark where even frontier LLMs struggle. Then we walk through one concrete example to see where one-shot reasoning breaks down. In the third part, we describe the physics-intern framework, a multi-agent system with specialized roles, adversarial review at every stage, and a persistent research state. We then show how it solves the example problem. Finally we scale it up to the full CritPt benchmark, where it sets a new state-of-the-art on the leaderboard, as shown in the chart below.
Over the past months, a few high-profile results have demonstrated that Large Language Models can help research in theoretical physics. OpenAI announced that an “internally scaffolded GPT 5.2 Pro” had helped find single-minus amplitudes for gluons and gravitons (Guevara et al., 2026) (we wrote a pedagogical explanation of these results here). Prof. Matt Schwartz at Harvard has been using Claude Code for particle physics calculations (Schwartz, 2026). And Joseph Tooby-Smith formalized a two-Higgs-doublet model stability result in Lean, uncovering an error in the original literature (Tooby-Smith, 2026).
Compared to other domains like coding or machine learning research, theoretical physics is hard for autonomous agents, because they have no way to get a reliable feedback signal. As suggested in the anonymous quote (that one of us remembers hearing during his studies), theoretical physics does not involve experiments (at least at first), but it is not formalized enough to rely on formal proof systems like Lean, now increasingly used in mathematics and AI-assisted research. This combination makes theoretical physics a particularly hard and interesting challenge for AI models, and is why the CritPt benchmark was created (Zhu et al., 2025).
1. The CritPt benchmark
CritPt (for Critical Point) is a benchmark of 70 research-level theoretical physics problems, covering quantum field theory, general relativity, statistical mechanics, quantum information, and more. Each problem has a definite answer (a formula, a number, a function), to be given as a SymPy expression.
Have a look at the leaderboard: even frontier models at maximum reasoning settings don’t get very far, with a maximum score of 30.6% (GPT 5.5 Pro at maximum reasoning effort) as of May 2026. Compare this with coding benchmarks where these models score 70-90%, or even Humanity’s Last Exam, a broad multi-disciplinary reasoning benchmark, where all the best models are between 25% and 45%. As of today, CritPt is one of the hardest benchmarks on which LLMs are evaluated.
To get a concrete sense of what CritPt asks, here are five example problems drawn from the benchmark, spanning quantum gravity, biophysics, nonlinear optics, and special functions. The dots beside each tab indicate the difficulty (1 = standard formulas, 5 = cutting-edge research level).
Holographic Weyl anomaly in 8 dimensions.
Consider a quantum field theory with holographic dual. Under a Weyl transformation, the boundary metric transforms as . The Weyl anomaly of the theory in dimensions appears in the transformation of the partition function:
It can be computed from the on-shell action of the bulk gravitational theory. In the anomaly can be expressed using the auxiliary tensors
plus analogous quantities and built from second derivatives of and contractions of the Weyl tensor . The anomaly then takes the form
where is a linear combination of , , , , , , , , , , .
Question: determine the eleven coefficients of these terms in .
Asymptotic growth of a noisy bacterial population.
Consider a population of genetically identical bacterial cells in balanced growth. Each cell starts with size and grows according to
where the growth rate is a two-state stochastic process that jumps between values and , with gamma-distributed waiting times of density
Each cell divides symmetrically when its size reaches
where controls cell-size regulation and is a narrow Gaussian division noise of variance . A population of such cells grows asymptotically as .
Question: find in terms of , , , , , , to first order in . Explain how and affect the growth rate.
One-point function in AdS₃ / BCFT₂.
In the AdS/BCFT correspondence, consider a bulk black hole geometry of inverse temperature :
with and , terminated by a spherically symmetric brane of tension behind the horizon. Let be a scalar primary operator in the BCFT, dual to a bulk scalar of mass , inserted on the Euclidean time-reflection slice .
Question: using the geodesic approximation, determine the form of the one-point function and its dependence on , , and .
High-harmonic generation with structured light.
Three temporally identical laser pulses (800 nm, 50 fs FWHM) are focused into a gas jet, with peaks at fs. The first is left-circularly polarized and carries orbital angular momentum ; the second is right-circularly polarized with ; the third is left-circularly polarized with . The pulses are overlapped in space and drive high-harmonic generation to produce EUV light.
Question: calculate the orbital angular momentum and helicity of the 23rd harmonic order.
Derivative of a hypergeometric function.
Let be a real parameter and define, for complex ,
where is the Gaussian hypergeometric function.
Question: evaluate
in closed form for .
Why is it so hard for models to do theoretical physics when most of them excel at coding and mathematics? Because the problems require long chains of reasoning with no room for error. A wrong sign, a missed boundary condition, or a subtle overcounting, and the whole derivation falls apart. There’s no linter or compiler to catch your mistakes, or test suite to run. You need to maintain an entire calculation, spot your own errors, and know when to abandon a dead end.
And by default, LLMs try to do everything in one shot. Very often, they commit to an approach early and struggle to revise it, with no external check to catch errors. They’re like a brilliant but overconfident graduate student working alone with no one to talk to.
To see this concretely, the next section zooms in on one specific CritPt problem with a public solution, and looks at exactly where a model goes wrong.
2. A quantum error detection puzzle
The CritPt benchmark has one example challenge with a public solution, a problem in quantum error detection. Let us describe it briefly; it will help see exactly where AI models go wrong.

In quantum computing, we use quantum bits, or qubits, instead of ordinary bits. A quantum computer tries to manipulate many such qubits to perform its computation. The problem is that quantum computers are inherently noisy: every operation on a qubit has a small chance of introducing a random error that corrupts the computation.
To protect against this, you can spread the information and exploit redundancy: you use more “physical” qubits than the necessary number of “logical” qubits. By running certain checks on the results, you have a chance to catch errors and redo the computation when needed. This is quantum error detection and correction. But it is not foolproof, sometimes a corrupted calculation slips past the checks. For a noise level (a probability of corruption), a given circuit will exhibit a certain fidelity : the probability that the state is actually uncorrupted given that it passed the checks.
The specific problem: in a configuration where 4 physical qubits encode 2 logical qubits, find as a function of the noise probability. Finding the answer requires tracking every possible combination of errors across the different noisy gates (about a million scenarios), figuring out which ones get caught by the check and which sneak through, and sorting the sneaky ones into harmless versus harmful. This is a massive but finite exercise in bookkeeping.
The answer turns out to be a rational function of with terms up to in both numerator and denominator:
The exact coefficients aren’t the point. What matters is the structure: when you expand for small , the leading correction is with no first-order term. This is what’s called a “fault tolerant” configuration, and it’s an important sanity check that any candidate answer must satisfy.
What happens in a one-shot scenario
We ran Gemini 3 Flash Preview on this problem 40 times and compared the answer to the ground truth using a SymPy comparison. It led to only 2 successes out of 40 runs (5%). Most runs gave the same wrong answer: . The model consistently concluded that the fidelity is perfect, directly contradicting the problem premise. A noisy circuit cannot have zero degradation; if it could, you’d have built a perfect quantum computer from a single round of error detection. But the model doesn’t catch this, because it lacks any mechanism for saying “wait, seems too good, let me double-check.”
Several of the remaining runs produced complicated but wrong formulas. In particular they all had a first-order term in , violating the fault-tolerance constraint we expect.
At (no noise), this evaluates to , not even in the valid range for a probability! The model produced it without noticing.
The model latches onto a first intuition (“single-gate errors are all detectable, therefore fidelity is 1”), commits to it, and never looks back. Yet the problem itself is perfectly amenable to a divide-and-conquer approach. It can be broken into manageable pieces: first verify the ideal circuit, then analyze single-gate errors, then tackle multi-gate combinations. Each piece gets checked independently before being combined. There are checks and balances at every stage, specifically designed to prevent the kind of tunnel vision that trips up a lone reasoner.
When a physicist tackles a hard problem, they very often don’t work alone. There’s a whole ecosystem: a PI outlines the strategy and plans a divide-and-conquer approach, a student does the calculation, and a colleague might check the work. When submitting the paper, referees are here to challenge the assumptions and an editor can overrule the reviewers’ decisions. And if someone finds an error, the team backtracks and revises.
What if a single autonomous agent could carry that whole ecosystem inside? This is the idea behind physics-intern: from the user’s side, an intern you hand a problem to; under the hood, a simulated research lab with specialized roles and adversarial review at every stage.
3. The physics-intern framework
physics-intern is a multi-agent scaffolding system that takes a physics problem and works through it autonomously: breaking it into sub-problems, performing calculations, writing and running verification code, reviewing its own results.
The design rests on three principles.
-
Specialization: Each LLM call attempts one limited task and receives only the context it needs. For instance the agent that plans the research strategy never sees the raw computations. Or the agent that reviews a result doesn’t have access to the detailed reasoning that produced already established results.
-
Checks and balances: No single agent can derail the process because every result gets adversarial review. Reviewers are invoked to check every intermediate candidate result, and on top of that a periodic “senior critic” checks whether the whole research direction makes sense. If a previously established result is challenged, an independent adjudicator evaluates the claim, so there’s always a second opinion.
-
Fresh context every call: No conversation history carries over between agents. A structured
ResearchStatepersists (the accumulated results, evidence, hypotheses, critiques), and a carefully assembled context is built from it for each new call. This prevents the compounding of errors that plagues long LLM conversations. Each run lives in its own workspace directory tracked as a git repository, with one commit per iteration, so every run is fully replayable, auditable, and resumable from any iteration.
One research loop, nine agents
The system uses 9 agent roles, each with a narrow remit and its own context.
| Agent | Role |
|---|---|
| Surveyor | Maps the research landscape: relevant techniques, key insights, known pitfalls. Runs once before the main loop. |
| Planner | Lays out the research strategy and the list of sanity checks the answer must satisfy. Revises the plan when a critique demands it. |
| Orchestrator | Reads the research state and decides what happens next: create a question, dispatch to a worker, promote a hypothesis. |
| Researcher | Performs analytical reasoning and derivations to produce evidence. |
| Computer | Writes and executes Python code in a sandbox to produce numerical or symbolic evidence. |
| Reviewer | Adversarially examines each candidate result; verdict: VERIFIED, REFUTED, or INCONCLUSIVE. |
| Senior Critic | Periodically audits the entire research state for cross-result coherence and strategy staleness. |
| Adjudicator | Independently arbitrates a critique filed against an Established Result. |
| Formatter | Produces the final answer once the orchestrator declares completion. |
Below we describe how these roles interact across the research loop. Before the main loop, a surveyor maps the research landscape (what techniques exist, what pitfalls to watch for) and a planner lays out the initial strategy, along with a list of sanity checks: testable pass/fail predicates the answer must satisfy (dimensional consistency, symmetry, limiting-case behavior, conservation laws). Sanity checks constrain the answer, not the process; they live in the research state and feed into both the computer (which validates its own results against them) and the critic (which can challenge an answer when a check fails). The planner owns the list and can add, revise, or retire checks when a critique triggers a strategy revision.
Inside the main loop, the orchestrator reads the current research state and decides what to do next. It creates Research Questions (RQ), formulates Working Hypotheses (WH), and dispatches work to either the researcher (analytical reasoning, derivations) or the computer (which writes and executes Python code in a sandbox).
Every hypothesis gets automatically sent to the reviewer, an adversarial agent that examines the evidence and issues a verdict: VERIFIED, REFUTED, or INCONCLUSIVE. Verified hypotheses with all their dependencies satisfied get promoted to Established Results (ER).
Periodically, a senior critic audits the entire research state, checking for coherence between results and questioning the overall strategy. If a critique targets an Established Result, it goes to the adjudicator for independent evaluation. If it questions the strategy, it triggers a planner revision (but the planner is always free to accept or reject the critique). When the orchestrator decides everything is resolved, it triggers completion and a formatter produces the final answer, though the formatter can bounce back to the orchestrator if the set of Established Results is not enough to produce an answer satisfying the problem statement and the answer template.
The typical lifecycle of a claim is then: research question → evidence → working hypothesis → review → established result. But at any point, the critic can challenge a result, the adjudicator can demote it, the planner can revise the strategy. Claims can go backwards, not just forwards.
Example role descriptions
Below are simplified versions of the prompts given to three of the nine agents. Each prompt fixes the agent’s role, its allowed inputs, and the structured context it receives from the ResearchState.
The orchestrator reads the research state and decides what to do next: create a research question, dispatch to a worker, promote a hypothesis.
Orchestrator prompt
You are a focused executor agent in a scientific research system. Your role is to follow the current strategy step by step: integrate evidence, manage research documents and dispatch the right worker for the next task.
(...)
## Research Framework
The research progresses through three entity types:
- Research Questions (RQ) — atomic questions, each answerable by a single agent call.
- Working Hypotheses (WH) — concrete, falsifiable claims with specific values.
- Established Results (ER) — verified WHs promoted automatically after review.
Typical lifecycle: RQ → researcher/computer produces evidence → WH (auto-triggers review) → reviewer checks → ER.
(...)
## Task
1. Manage the research state — integrate new evidence, manage hypotheses, maintain research notes.
2. Dispatch next task — formulate a clear focused task for the researcher or computer agent.
(...)
---
<research-context>
<problem-statement> ...
<answer-template> ...
<problem-guidelines> ...
</research-context>
<background-survey>
<background> ...
<key-insights> ...
<known-methods> ...
<known-pitfalls> ...
</background-survey>
<research-state>
<conventions> ...
<strategy> ...
<sanity-checks> ...
<established-results> ...
<hypotheses> ...
<research-questions> ...
<dead-ends> ...
<research-notes> ...
<dispatch-history> ...
</research-state>
>>> EVIDENCE RESULTS <<< (when a worker just returned)
>>> VERIFICATION RESULTS <<< (when a review just completed)
>>> SYSTEM EVENTS <<< (critique routing, ER demotions, ...)
The computer writes and executes Python in an isolated sandbox. Each call is stateless: no kernel state carries over, so every script must be self-contained.
Computer prompt
You are a computational agent in a multi-agent scientific research system. You produce computational evidence — numerical results, symbolic computations, or simulations — for a specific research question or hypothesis assigned to you by the orchestrator. Your work will be reviewed by an independent reviewer.
## Workflow
- First turn — call ONLY `document_approach`, describing what you will compute, how, and why. Do not execute code yet.
- Subsequent turns — use `execute_python` to produce results. Each call runs in a completely isolated Python process; every script must be self-contained, with sanity checks.
- Final turn — call `submit_result` with findings, method, and confidence level (`exact` / `approximate` / `partial`).
(...)
## Exploration Strategy
- Physics self-validation: check dimensional consistency, evaluate at least one limiting case, verify parameter scaling and symmetries.
- Independent numerical cross-check: when the result is a symbolic formula, also compute it by a different route (brute-force enumeration, matrix mult, Monte Carlo). Disagreement means a bug — do not submit until resolved.
(...)
---
<research-context>
<problem-statement> ...
<answer-template> ...
<problem-guidelines> ...
</research-context>
<research-state>
<conventions> ...
<established-results> ...
</research-state>
<task>
<target> ... (the RQ or WH to investigate)
<background> ... (strategic context, survey material)
<instructions> ... (what to produce)
<method-hints> ...
<assumptions> ...
<relevant-results> ...
<recommended-sanity-checks> ...
</task>
The senior critic audits the research state at a strategic level. Unlike the per-claim reviewer, it looks for cross-result contradictions, stale strategies, and missing validation.
Critic prompt
You are the Senior Critic of a scientific research system. Your role is to perform high-level review of the research strategy and the coherence of established results.
## Task
Be the reviewer of the big picture and formulate critiques when they are needed: contradictions between results, evidence the system is ignoring, strategy staleness, missing validation. You are not the per-claim reviewer.
Your critiques are routed based on `target_type`:
- `ER` → sent to an independent adjudicator for evaluation
- `strategy` / `coordination` / `sanity_check` → trigger planner revision
(...)
## What to Examine
- Strategy — consistent with evidence? recommending a refuted path?
- Result coherence — do established results form a logically consistent chain?
- Scope — does the answer reflect the full complexity implied by the problem?
- Sanity checks — boundary values, dimensionality, conservation, symmetries.
- Termination readiness — when established results, taken together, already determine the answer required by the answer template, file a `coordination` critique recommending termination.
(...)
---
<research-context>
...
</research-context>
<background-survey>
...
</background-survey>
<research-state>
<conventions>
<strategy>
<sanity-checks>
<research-questions>
<hypotheses>
<established-results>
</research-state>
<previous-critiques>
<critique> ... (to avoid duplicates)
</previous-critiques>
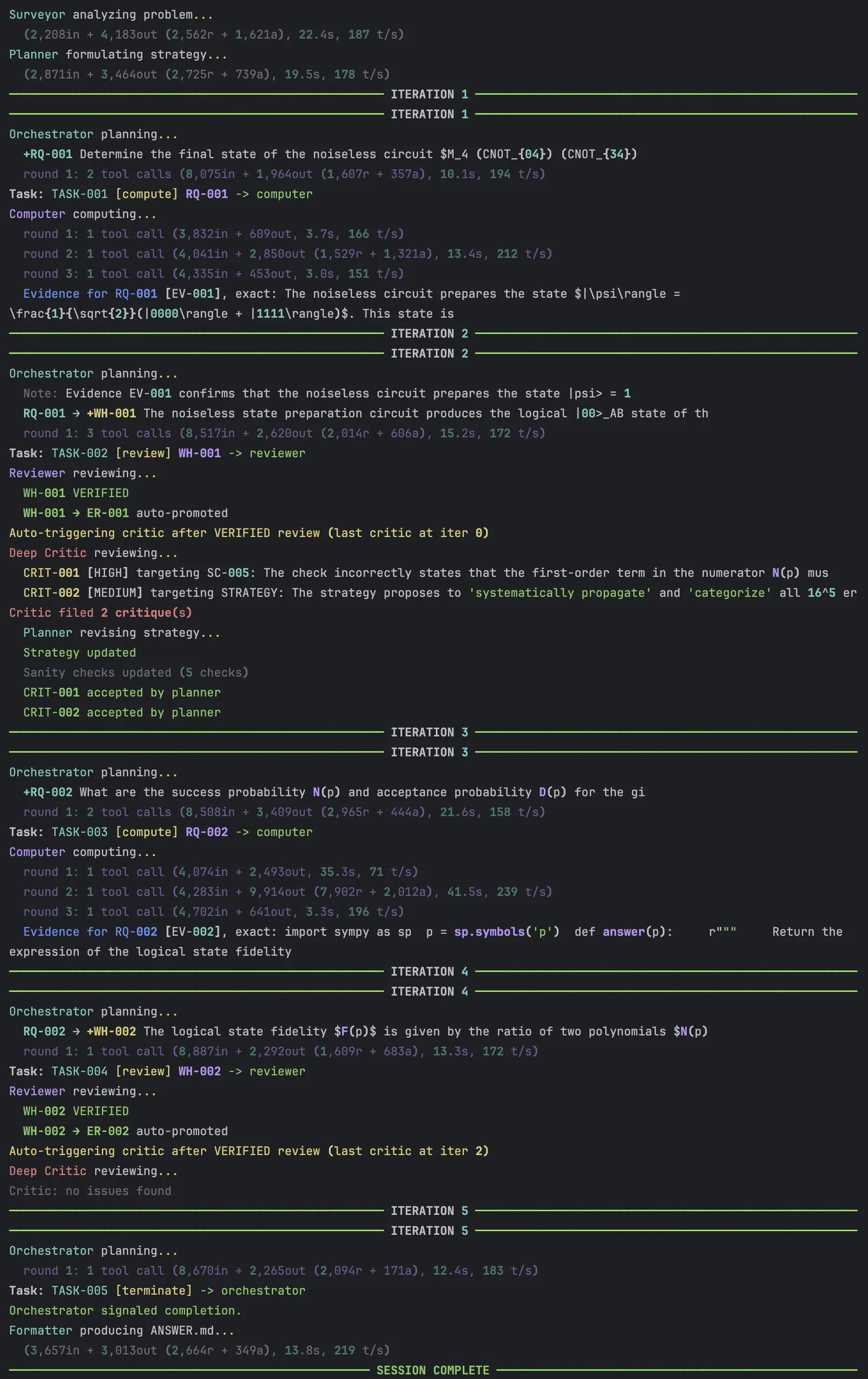
The console log below illustrates the dynamics at play between the different agents iteration after iteration.
4. Solving the example puzzle with physics-intern
With the architecture in place, the natural test is the puzzle from §2. We ran the same quantum error detection problem through physics-intern using Gemini 3 Flash. Across 20 runs, it succeeded every single time (vs 5% success in one-shot mode).
More telling than the success rate is how the system gets there. It did not always follow the same golden path: it tried different strategies, made mistakes and self-corrected, but finally reached the same answer every time through different routes. Here are some example runs to illustrate the dynamics.
Example runs
Below are a few example runs that illustrate how the system works.
In this first run, everything ran perfectly well in just 3 iterations with no failures.
Clean run (3 iterations)
First, the surveyor mapped the problem, and the planner laid out a strategy: verify the ideal circuit, enumerate all error configurations, classify them, compute the fidelity.
The orchestrator decided to create a unique research question (RQ) with this and assigned it to the computer agent. Three iterations later, it had the answer. The orchestrator then created a working hypothesis with this candidate answer, and it was automatically sent to the reviewer agent. The reviewer had the claim, the code written by the computer agent, and its output. It verified it and also applied sanity checks like (no noise, perfect fidelity), (maximum noise, nearly random outcome among 4 logical states), and the leading correction scales as , confirming the fault tolerance property.
The reviewer ruled the evidence was valid, and the working hypothesis was thus promoted to an “established result.” No critiques were filed by the critic so the orchestrator ordered the termination. The whole process took 3 iterations, 10 LLM calls, and about 160K tokens.
In the second run, the critic raised a false flag that was overturned by the adjudicator. This is the system working as designed: the critic is supposed to be adversarial, but in case of a mistake, the adjudicator has a chance to sort signal from noise.
The false alarm (3 iterations)
In this run, the strategy was the same, and so was the initial path: the orchestrator dispatched a computer agent which produced the (correct) answer, it created a working hypothesis, the reviewer checked the evidence and this was promoted to an established result. But this time the senior critic fired! The critic (incorrectly) claimed the fidelity expression violated physical bounds: ”, exceeding maximum fidelity of 1.” So it raised a critique against the established result.
The claim and the critique were automatically routed to the adjudicator agent for a decision. The adjudicator plugged in and got approximately 0.25. The critic had made a computational error in its own evaluation! So the adjudicator ruled in favor of the original evidence, and dismissed the critique.
The third run took a more cautious path: instead of jumping straight to the full enumeration, the planner split the work into two explicit research questions, validating each separately.
The thorough investigation (5 iterations)
The planner broke the problem into two explicit research questions: first validate the target state using stabilizer tableau methods, then compute the fidelity.
The first result (ER-001) confirmed the noiseless circuit prepares the correct state by tracking stabilizer generators through each gate. The second (ER-002) performed the full error enumeration using two independent methods (symplectic propagation and distribution tracking) that converged to the same answer. Two critiques were filed by the critic, but both were dismissed after adjudication. 5 iterations, 16 LLM calls, about 288K tokens.
All three runs produced the identical correct answer, but using 3 different paths.
Here you can see the GitHub repo of a more complete example spanning 7 iterations (including an initial result being proved and reviewed, before being demoted following a critique and adjudication).
Comparison with other approaches
Recursive Self-Aggregation (RSA)
The simplest way to spend more compute on a hard problem is to run many independent attempts and aggregate them. Recursive Self-Aggregation (RSA) (Venkatraman et al., 2025) does this through a tournament, by running many candidate answers and successively picking winners. Recursive Language Models (Guan & others, 2025) go further: a main model delegates subtasks to sub-LLMs, manages a persistent code environment, and actively folds its context to prevent the degradation that comes with long conversation histories.
We ran RSA on the example quantum detection challenge with Gemini 3 Flash, using , , — about 24 LLM calls per problem, roughly 20× the cost of one-shot. RSA solved the problem 35% of the time: a clear improvement over one-shot’s 5%, but well short of physics-intern’s 100%. In this case, more compute alone helps, but doesn’t close the gap. A closer look at the solutions generated shows that if most of the first runs fall into the trap of conjecturing a wrong answer (here , like the one-shot runs), then RSA will only remix these wrong answers and never realize it has fallen into a trap.
AutoPhysicist: could we create a simpler system?
The physics-intern design might look overly complicated, with 9 agents holding different roles. This is in contrast with actual physics research where the role division is much more blurry and the same person usually wears several hats.
We tried a much simpler scaffolding system called AutoPhysicist with only one hard-coded agent, the manager in charge of spawning sub-agents and entirely writing their prompts at run-time. The manager maintains a permanent memory file (fully visible every iteration) and a scratchpad with a sliding window (only the last 5 entries shown).
AutoPhysicist manager prompt
You are the Research Manager of an autonomous research system designed to make progress on problems in theoretical physics and mathematics. You are the sole decision-maker. You control what gets investigated, how results are verified, and what is recorded as established knowledge.
(...)
## Your tools
### `dispatch_subagent(system_prompt, user_message, execute_code=False)`
Creates a temporary agent, gives it the system prompt and user message you wrote, and returns its response to you.
(...)
### `write_to_permanent_memory(content)`
Appends text to the permanent memory file.
(...)
### `write_to_scratchpad(content)`
Appends text to the scratchpad. Only the last 5 entries are visible to you. Use this for working notes, hypotheses, plans, status updates, and intermediate results that have not yet been verified.
(...)
This approach reaches 85% on the example problem, a clear gain over baseline and RSA but still behind physics-intern’s 100%. The gap suggests that explicit role separation, with each agent receiving only the context it needs, is doing real work that a generalist manager can’t fully replicate.
The four systems span the spectrum from one-shot to fully structured. Throwing more compute at the same prompt (RSA) helps modestly. A manager spawning subagents (AutoPhysicist) helps more. Only physics-intern’s structured multi-agent process, with explicit roles, adversarial review, persistent state, gets there reliably.
5. Scaling up: the full CritPt benchmark
Results
The examples above are one problem, and it’s arguably one of the easier ones compared to the average difficulty of the CritPt benchmark. What happens across all 70? We can’t know the details because the solutions of the benchmark are private, but after submitting to the CritPt benchmark through their API, we can look at global results.
We ran the full CritPt benchmark with physics-intern on Gemini 3 Flash, Gemini 3.1 Pro, and Kimi K2.6 (an open-weights model) and compared to their baseline scores on the CritPt leaderboard.
| Setup | Score |
|---|---|
| Gemini 3 Flash | 8.6% |
| Gemini 3 Flash + physics-intern | 15.7% |
| Kimi K2.6 | 8.0% |
| Kimi K2.6 + physics-intern | 21.4% |
| Gemini 3.1 Pro | 17.7% |
| Gemini 3.1 Pro + physics-intern | 31.4% |
The multi-agent framework lifts Flash from 8.6% to 15.7% and Pro from 17.7% to 31.4%, roughly an 80% improvement in both cases. The boost is even more dramatic for Kimi K2.6, which jumps from 8.0% to 21.4% — a 168% relative gain that nearly triples its baseline and brings an open-weights model above several frontier closed models at maximum reasoning. At 31.4%, Gemini 3.1 Pro + physics-intern slightly surpasses the previous best entry on the CritPt leaderboard (GPT 5.5 Pro at maximum reasoning, 30.6%), making it — to our knowledge — the highest score recorded on CritPt to date. And this is achieved using a model whose own raw score is 17.7%.
Here’s how physics-intern compares to frontier models on the CritPt leaderboard:
The cost-vs-score plot tells the story more sharply than the raw numbers. In particular, Gemini 3.1 Pro + physics-intern climbs above the previous leaderboard top at materially lower cost than the GPT Pro family it has now overtaken. The same plot also includes Gemini 3 DeepThink, which spends much more compute through extended reasoning (about $10 per problem on average) yet lands at 25.7%, well below physics-intern + Gemini 3.1 Pro at 31.4% for less than $5/problem. This echoes the RSA result on the example puzzle: a dedicated, structured harness extracts more from a base model than dumping a comparable amount of compute into unstructured reasoning.
Analysis of runs and agent behavior
The run statistics on Gemini 3.1 Pro give a sense of how physics-intern distributes effort across difficulty. The average number of tokens was about 600k (roughly equal split between input and output). Per-problem token usage spans more than one order of magnitude — from 113K on the cheapest problem to 3.9M on the most demanding — with iterations ranging from 3 up to 40 (median 8 iterations, mean 28 LLM calls per problem).
From these numbers we can confirm the example puzzle from §2 sits at the easy end of this distribution, so it is not representative of the benchmark as a whole. On the harder problems of the whole CritPt benchmark, the loop runs much longer, and the senior critic fires more often (234 critiques in total across the 70 problems, median 2, max 15). About 15% were targeting a specific Established Result (ER). The critique was then escalated to the adjudicator which ruled in favor of the critic 60% of the time (ER was then demoted), but dismissed it 40% of the time. Most of the critiques (85%) were targeting not a specific result but rather coordination or strategy, and were resolved by the planner.
What’s perhaps most striking is the breakdown of work: across the full run the system spent roughly as much output on review and critique (reviewer + senior critic + adjudicator ≈ 37% of output tokens) as on doing the work itself (computer + researcher ≈ 36%). On a benchmark this hard, roughly as much compute goes into checking the answer as into producing it.
There is also a more qualitative advantage. Because physics-intern mimics the structure of actual research (a planner sets the strategy, a researcher does the work, a reviewer checks it, a critic challenges it…) the whole process is legible to a human physicist. At any point, a human can inspect the research state, comment on a hypothesis, redirect the strategy, or hint at an approach the agents missed. This makes human-in-the-loop collaboration natural: you’re joining a process that already looks like the way research is done. By contrast, RSA runs many independent LLM calls in parallel and selects among them through a tournament, a process that has no natural point of human entry and no persistent state a physicist could meaningfully steer.
6. Open-weights results: Kimi K2.6
Kimi K2.6 + physics-intern scores 21.4% on CritPt, up from 5.7% in one-shot mode on the same hardware. This is our first open-weights run, and it confirms that the lift we saw on the Gemini models transfers to a meaningfully different model. Notably the relative lift on Kimi (about 3.7x) is roughly twice what we saw on either Gemini variant (about 1.8x in both Flash and Pro): the scaffold helps a weaker base model more, largely because one-shot Kimi fails on a structural problem (running out of output budget) that the multi-agent loop routes around.
| Setup | CritPt score | Tokens / problem (median, in+out) | Wall clock (full 70 problems) | Dominant failure mode |
|---|---|---|---|---|
| Kimi K2.6 + one-shot | 5.7% | ≈66K | ≈49 min | 56/70 truncated at 65K output cap |
| Kimi K2.6 + physics-intern | 21.4% | ≈1.0M | ≈5h | rare per-agent truncations |
Both setups ran on the same 256-H100 serving stack (8 vLLM replicas × 32 H100s each); the wall clock numbers reflect that one-shot dispatches all 70 problems concurrently while physics-intern is sequential within a problem (about 32 LLM calls per problem with data dependencies, around 3.5h median per problem).
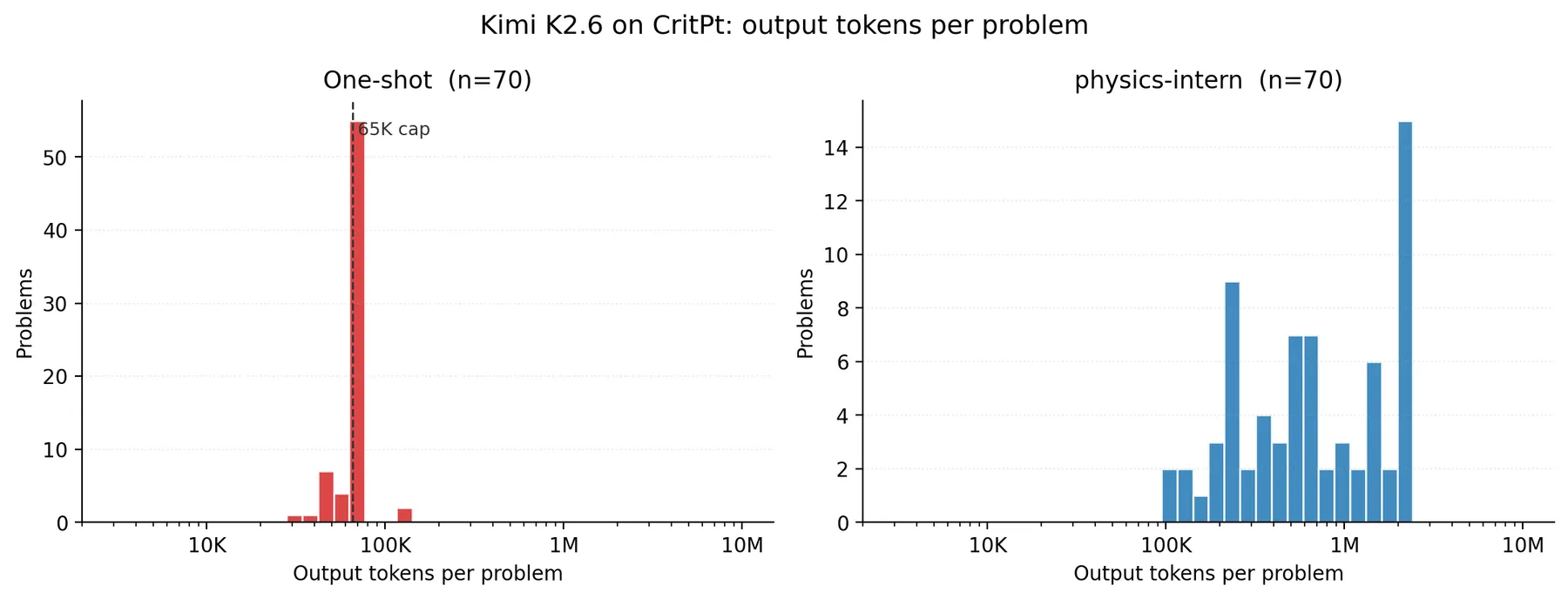
Kimi K2.6, one-shot
Locally served Kimi K2.6 in one-shot mode scores 5.7% on CritPt (4/70 correct), close to the 8.0% reported on the public leaderboard. The headline finding is not the score itself but the failure mode: 56/70 problems (80%) hit the 65,536 output-token cap mid-reasoning and never emitted a final answer. Mean output is 64K tokens per problem (median exactly 65,536), for a total of 4.5M output tokens in 49 minutes of wall clock across 8 vLLM replicas (about 36h cumulative compute). Even on the 14 problems where Kimi did emit an answer, only 4 were correct, so analytical errors are real too. But the dominant failure mode is structural: one-shot Kimi runs out of room to think before reaching an answer.
Kimi K2.6 + physics-intern
Same model, same hardware, 5.7% → 21.4%: a +15.7pp absolute lift, or about 3.7x relative. The scaffold solves 15/70 problems where one-shot solved 4. The cost is large in tokens (about 1.4M total or 943K output per problem on average, roughly 15x one-shot) but distributed across a median of 10 iterations and around 32 separate LLM calls, so the 65K output cap becomes a per-call ceiling rather than a hard wall. Truncations still happen (they show up as max_tokens_reached alerts in the per-iteration metrics tables), but they hit individual agent calls that the scaffold’s retry-on-truncation path routes around, not the whole run. The same structural cap that strands one-shot Kimi becomes a recoverable per-call event under physics-intern.
Running large open models locally
The open-weights story only works if the models actually run. Kimi K2.6 has about 1T parameters (around 800GB on disk), and GLM 5.1 and DeepSeek V4 are in a similar class. None of them fit on a single node, and any benchmark sweep needs many concurrent requests across replicas. We built the serving stack inside the same repo so the eval client never has to know about Slurm. Three files do the work:
serve/serve.slurm: a self-submitting Slurm job that launches vLLM in TP/PP/DP across N nodes, resolves model-specific defaults (TP, PP, vLLM flags, reasoning parser) frommodels.yaml, arms an idle watchdog so unused serve jobs auto-cancel after 2h, and restarts vLLM up to N times on crash.serve/multi_serve.sh: submits multiple independent replicas as parallel Slurm jobs. We use it to launch e.g. 4 normal-QOS replicas plus an auto-sized pool of opportunistic low-QOS, requeueable replicas that grab whatever capacity is currently idle on the cluster.serve/load_balancer.py: async round-robin LB exposing a single/v1endpoint, discovers new replicas from Slurm every 10 minutes, removes dead backends, and caps concurrent in-flight requests per replica.
For Kimi K2.6 the canonical shape is PP=4 × TP=8 × 4 nodes/replica × 4 to 8 replicas, i.e. 128 to 256 H100s for one benchmark sweep. PP=2 OOMs under concurrent load at 262K context, so the extra pipeline stages buy KV headroom rather than throughput.
The full tuning record is in models.yaml. Three things mattered:
- Dropping
--enforce-eagerwas a 4x throughput win (about 22 to 92 tok/s single-request on Kimi). Kimi’s CUDA-graph and torch.compile paths work fine, unlike GLM’s where eager mode stayed necessary. This was the single biggest delta in the whole sweep. --enable-expert-parallel+--safetensors-load-strategy prefetch+ thekimi_k2tool/reasoning parsers. Expert parallel adds a few percent on single-request and is free. Prefetch only matters on cold WekaFS (first ever load took 78 minutes without it, about 7 minutes with), but is a no-op once warm. The matching parsers are non-negotiable: vLLM rejectstool_choice="auto"without them.- Speculative decoding is blocked on Kimi K2.6. Under PP > 1 on vLLM 0.19.1 there are two upstream bugs (one workaroundable, one not). The alternatives are all closed too: K2.6 dropped K2’s MTP layers, ships no EAGLE/Medusa draft weights, and arctic-inference fails to build against system GCC 9.4. FlashAttention 4 is also not an option on H100 (Blackwell-only), but Kimi already uses FA3, which is the latest on Hopper.
The same model is available through Moonshot’s API at $0.95 / $4.00 per 1M input / output tokens (Kimi K2.6 pricing). At our actual token usage, physics-intern + Kimi K2.6 comes out to about $4 per problem for 21.4%, against around $14 per problem for GPT 5.5 Pro at 30.6% on the leaderboard. Lower accuracy ceiling, but a quarter of the cost and competitive on $-per-percentage-point with the best proprietary entries.
7. What comes next
Lifting Gemini 3.1 Pro from 17.7% to 31.4% puts it slightly above the previous CritPt leaderboard top (GPT 5.5 Pro at 30.6%). More striking, in our view, is that physics-intern on Gemini 3 Flash, a smaller model, lands alongside much larger frontier models running at maximum reasoning. On a benchmark this hard, scaffolding can substitute for scale.
Several directions look worth pursuing.
Open models: Our Kimi K2.6 result (8.0% → 21.4%) already shows the lift carries over to open-weights models — in fact with a larger relative gain than on the Gemini models. We plan to extend this to DeepSeek V4 and GLM 5.1, which start lower than their closed counterparts but may close most of the gap if scaffolding adds a similar absolute boost.
Other proprietary models: The GPT 5.4/5.5 models rank above Gemini 3.1 Pro on the CritPt benchmark but our preliminary investigations seem to indicate that they do not benefit as much from the scaffolding we created. This might be explained by a better post-training that makes them more efficient at solving these kinds of problems. Anecdotal evidence and comparison with Gemini 3.1 on selected problems seem to show they sometimes fall for traps and converge too quickly and confidently to a wrong (but tempting) answer.
Better tools: Adding web search, a bibliography agent, and a Mathematica connector would move physics-intern from a benchmark solver toward an actual research assistant. The current sandbox is Python only, but a lot of the calculations a theoretical physicist does live in computer algebra land.
Architecture improvements: Some problems might benefit from parallelism of agents, either to explore several concurrent paths, or for redundancy in checking sophisticated evidence.
Open problems with human-in-the-loop: Benchmarks have known answers, but real research does not! Although certain aspects of the prompting of the agents explicitly refer to the existence of a solution, physics-intern already supports human-in-the-loop interaction: a physicist can inspect the research state mid-run, comment on a hypothesis, redirect the strategy, or hint at an approach the agents missed. Pointing the system at genuinely open questions is an obvious next step. Feel free to reach out to us if you want to try on your own research problem!
More broadly, theoretical physics is a useful stress test precisely because the feedback loop is so unforgiving: no compiler, no test suite, no Lean. If structured multi-agent coordination measurably helps here, it likely helps wherever long, error-sensitive chains of reasoning are the bottleneck.
The full code is open-sourced on GitHub at physics-intern.
Many thanks to Leandro von Werra, Ben Burtenshaw and Thom Wolf at Hugging Face for fruitful discussions during the project.
Appendix: Gemini 3.5 Flash
After this article was first written, Google released Gemini 3.5 Flash. We ran the full CritPt benchmark with the new model, both in one-shot mode and with physics-intern.
| Setup | Score | Cost per problem |
|---|---|---|
| Gemini 3.5 Flash | 13.1% | $0.44 |
| Gemini 3.5 Flash + physics-intern | 22.9% | $3.67 |
The scaffold lifts the new Flash model from 13.1% to 22.9%, a +9.8pp absolute gain. The updated cost-vs-score chart below places both points on the leaderboard.
physics-intern is available on GitHub. The CritPt benchmark is at critpt.com. Leaderboard data from Artificial Analysis.
- Guan, J., & others. (2025). Recursive Language Models: Scaling Test-Time Compute via Self-Delegation. https://www.primeintellect.ai/blog/rlm
- Guevara, A., Lupsasca, A., Skinner, D., Strominger, A., & Weil, K. (2026). Single-minus gluon tree amplitudes are nonzero. https://arxiv.org/abs/2602.12176
- Schwartz, M. D. (2026). Resummation of the C-Parameter Sudakov Shoulder Using Effective Field Theory. https://arxiv.org/abs/2601.02484
- Tooby-Smith, J. (2026). Formalizing the stability of the two Higgs doublet model potential into Lean: identifying an error in the literature. https://arxiv.org/abs/2603.08139
- Venkatraman, S., Jain, V., Mittal, S., Shah, V., Obando-Ceron, J., Bengio, Y., Bartoldson, B. R., Kailkhura, B., Lajoie, G., Berseth, G., Malkin, N., & Jain, M. (2025). Recursive Self-Aggregation Unlocks Deep Thinking in Large Language Models. https://arxiv.org/abs/2509.26626
- Zhu, M., Tian, M., Yang, X., Zhou, T., Yuan, L., Zhu, P., Chertkov, E., Liu, S., Du, Y., Ji, Z., Das, I., Cao, J., Yu, J., Wu, P., He, J., Su, Y., Jiang, Y., Zhang, Y., Liu, C., … Peng, H. (2025). Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark. https://arxiv.org/abs/2509.26574